- Scrapy初学
- 介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(比如Web Services)或者通用的网络爬虫。Scrapy也能帮你实现高阶的爬虫框架,比如爬取时的网站认证、内容的分析处理、重复抓取、分布式爬取等等很复杂的事。
- 安装
感觉安装稍微有点麻烦,根据网上的教程,一直会爆各种错误,在linux上有点小问题一直没解决,最后还是选择在windows上安装。
软件包有

将C:\python27\Scripts放到环境变量中,因为Scrapy会安装在那个目录下。
Cmd下可以直接执行scrapy就说明安装成功。
- 使用
- 创建一个新的工程,感觉类似django。
在自己指定的目录下运行
scrapy startproject ckf
目录结构如下:
ckf/ scrapy.cfg # 部署配置文件 ckf/ # Python模块,你所有的代码都放这里面 __init__.py items.py # Item定义文件 pipelines.py # pipelines定义文件 settings.py # 配置文件 spiders/ # 所有爬虫spider都放这个文件夹下面 __init__.py
- 定义一个自己的item
通过创建一个item类并定义为scrapy.field属性,将想要爬的网站爬下来。(比如我要爬cslg新闻网)
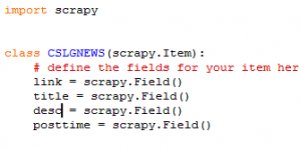
- 创建一个spider
蜘蛛就是你定义的一些类,Scrapy使用它们来从一个domain爬取信息。 在蜘蛛类中定义了一个初始化的URL下载列表,以及怎样跟踪链接,如何解析页面内容来提取Item。
定义一个Spider,要继承scrapy.Spider类并定义一些属性。
在/ckf/spider/目录下可以创建一个cslgnews_spider.py
内容需要根据网站代码来写。
创建完后可以运行爬虫
Scrapy crawl cslg
- 设置基本设置
数据可能需要保存在数据库中,所以要将数据库设定好,类似django的setting.py。
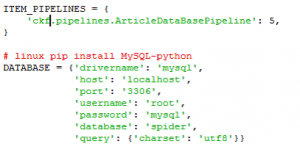
这样的话,scrapy的基本特性可以初步领悟一下。
- 前期准备
看一下xpath的语法。因为scrapy来匹配代码的具体位置时,采用的不是正则匹配,而是xpath。具体xpath的语法和详细内容,可以看w3School的教程:http://www.w3school.com.cn/xpath/xpath_syntax.asp。
基本匹配规则我写一点:
部分路径表达式:
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
当想要选取未知节点的时候:
| 通配符 | 描述 |
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
- 实例
爬取web.cse.cslg.cn/?cat=72的所有新闻的链接和题目。
1)代码
# -*- coding: utf-8 -*-
import scrapy
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from scrapy.http import Request
from scrapy.selector import Selector
from ckf.items import CkfItem
class CseSpider(scrapy.Spider):
name = "web"
allowed_domains = ["web.cse.cslg.cn"]
start_urls = ['http://web.cse.cslg.cn/?cat=72&page=1']
def parse(self, response):
#for sel in response.xpath('//u1/li'):
item = CkfItem()
selector = Selector(response)
news = selector.xpath('//div[@class="cat-post-lists"]')
for sel in news:
se = sel.xpath('ul[@class="post-lists-ul"]/li')
for s in se:
#title=selector.xpath('/a/text()').extract()
#link=selector.xpath('/a/@href').extract()
item['title'] = s.xpath('a/text()').extract()
item['link'] = s.xpath('a/@href').extract()
yield item
2) 代码结构
项目配置文件(./ckf/settings.py)
配置文件的基本信息不用改,如图:
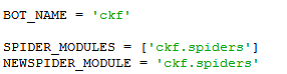
我们可以自行修改user-agent,并且做一些其他操作,比如保存结果为csv文件并定义文件存放路径。
![]()
Item文件(./ckf/item.py)
Items是将要装载抓取的数据的容器,它工作方式像 python 里面的字典,但它提供更多的保护,比如对未定义的字段填充以防止拼写错误。
通过创建scrapy.Item类, 并且定义类型为 scrapy.Field 的类属性来声明一个Item。
我们通过将需要的item模型化,来控制从web.cse.cslg.cn/?cat=72获得的站点数据,比如我们要获得新闻的标题和链接,我们定义这三种属性的域。在 ckf 目录下的 items.py 文件编辑。
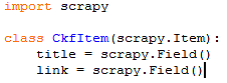
之后再spider中会用到。
Spider文件(./ckf/spider/cse.py)
代码结构当然是要首先遵循python的语法,其次是遵循scrapy的结构,其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。比如我代码中写的:
![]()
当然可以加上其他自己写的函数,最终在parse()中调用成功就可以了。
3)代码原理
查看http://web.cse.cslg.cn/?cat=72&page=1的源代码,右击一个新闻标题,选择检查,可以发现,所有的新闻都在div class=”cat-post-lists”的标签下:

本来想着可以在ul class=”post-lists-ul”标签下爬取,但是发现不知道怎么回事,好像有点问题,爬取数目为0。
而且我们还可以发现,每个新闻标题在li标签下的a标签中,那么我们可以用xpath对其位置进行匹配。
Response模块可以获得整个网页的信息,才可以让用户可以通过xpath进行匹配。
流程为,在所有div class=”cat-post-lists”(整个页面中此标签唯一)下进行选择,再在ul class=”post-lists-ul”下的li标签中进行选择,将a标签中的文本信息保存在item的title中,将a标签中的所有的href的内容写入item的link中(类似python的字典)。
根据setting中的设置,输出信息会产生一个csv文件。
4)运行回显及结果
运行scrapy crawl web(最后的是爬虫的名字),会回显爬取的内容
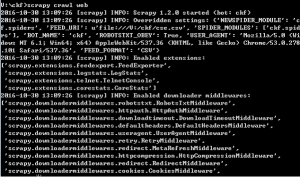
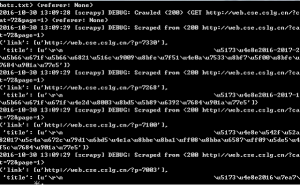
然后scrapy crawl web -o xxx.json保存为json文件,然后就会产生一个csv文件。然后打开json文件可以看到:

基本就是字典的形式。
然后看csv文件,分成了两列:
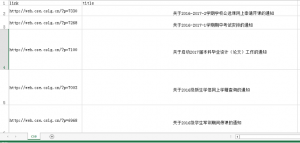
这样,想要爬去的信息就得到了。
- 遇到的小问题及一些进一步的想法
一开始写好是写好,但是发现所有信息都聚集在字典的一个元素里,后来才发现是我将所有的li标签放到了同一个循环里,导致实际上是将所有的新闻标签当成了一个整体。
在一开始的start_url中,其实可以多写几个页面,比如分别将新闻第一页第二页都爬取下来,但是,其实是可以写一个函数,自动翻页,只设置一个开始页面,不过可能写一次才能完成。
这一个小项目中,我并没有使用到pineline.py文件,他的功能为:
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
每个item pipeline组件(有时称之为ItemPipeline)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
一般大项目都会使用,下次可能会查实使用它。
- 实例改进
1)改进需求
上次的爬取我们学院新闻的爬虫本来是爬取一个页面的:
![]()
就是start_url只有一个页面。新闻有很多页,如果想爬取其他所有页面,其实主体代码不用变,因为标签几乎没变,只是多了start_url而已,可是我并不知道有多少页新闻,因为网站并没有写,只是一直显示下一页:
![]()
其实可以通过修改URL中的page的值来查看是否存在该页码,例如我输入http://web.cse.cslg.cn/?cat=72&page=40,当出现页码数存在时,会跳转至那个页面,但是当页码不存在时,会自动跳转到首页:
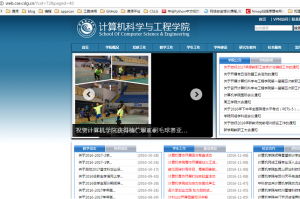
测试发现,新闻总共21页:
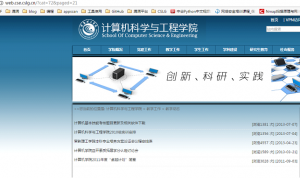
但是,最后一页是31页,因为没有“下一页”标签的才是最后一页:
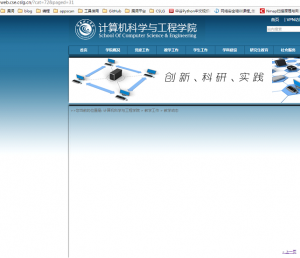
知道了页码,其实我们可以通过增加start_url来爬取1-8页的新闻:
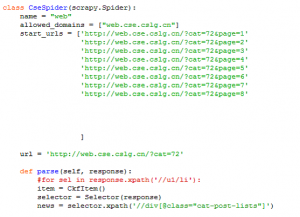
但是这样就感觉很不方便,页数多的时候,这样根本解决不了问题。
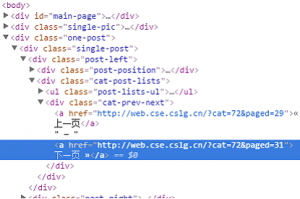
所以,我们可以写一个函数,来让爬虫爬取完一个页面之后,自己点击“下一页”的超链接:
2)改进时出现的问题
可以写几行代码来判断是否存在下一页并且爬取进如下一页:
nextLink = selector.xpath('//div[@class="cat-prev-next"]/a/@href').extract()
n=1
n+=1
if nextLink and n==1:
ne = nextLink[0]
print ne
yield Request(ne,callback=self.parse)
elif nextLink and n!=1 and n<=21:
ne = nextLink[1]
yield Request(ne,callback=self.parse)
elif nextLink and n>21:
quit()
因为第一页的时候class=”cat-prev-next”里面只有一个href,但是之后的每一页就有两个href,所有加了个n用作判断第几页,而超过21页时虽然也可能有两个href,但是却没有扫描的必要,直接break就好了。
程序运行的时候,发现不管怎么样只有两页的内容:

本来以为是代码写错了,不过之后排查才发现,原来的网站似乎一些url访问的限制,当我直接访问http://web.cse.cslg.cn/?cat=72&page=13的时候,网站还是显示第一页:
而当我点击下一页时,会出现:
![]()
这样便发现,每次爬虫获取到
一个源代码中的href就会重新访问一次那个url,导致回到首页,而scrapy有去重的功能,所以最后生成的结果就是第一页的爬取信息。
3)问题的解决
就在我排除代码问题的时候,我发现原来上面的n写的不对劲,每次运行parse函数时都会重新定义n=0,所以这样直接改成循环,就可以进行循环爬取。而之前说的url的问题,之后发现其实只是从非第一页url(http://web.cse.cslg.cn/?cat=72)访问才会导致访问错误,这样其实就证明了,我上一份报告写的start_url其实并不是真正的第一页,而是因为url(http://web.cse.cslg.cn/?cat=72&paged=1)非法而导致的重定向到第一页。
4) 改进的代码
for n in range(1,21,1): if nextLink and n==1: ne = nextLink[0] print ne yield Request(ne,callback=self.parse) elif nextLink and n!=1 and n<=21: ne = nextLink[1] yield Request(ne,callback=self.parse) elif nextLink and n>21: quit()
5) 结果展示
同样是scrapy crawl web来调用爬虫
Scrapy crawl web –o a2.json来输出结果
在第一条命令执行时,一个cse.csv文件会生成,结果也会保存在里面
我们可以看到,除去第一行,总共320条新闻链接:

文件夹新的目录如下:
scrapy在windows安装所需依赖和完整爬虫在这里。